Claude Code 基础分享IV - 提示词与工作流
什么是工作流
我不太希望把工作流和n8n搭建的自动化工作流混淆,n8n搭建的工作流很大程度上是为了适配固定的情景和模式,在我们的日常工作中,工作流更多是变化的,需要根据具体需求进行定制和调整。
好消息是这并非很复杂或者耗时,你更多的是在着手工作之前为任务制定一个小目标,然后试着思考如何达成它,你自己的工作流很大程度上是关于“我该如何操作claude code”,而不是我该如何搭建一个自动化工作流。
梳理你的工作
在任务开始之前,你需要至少做两件事
- 明确的目标
- 可被量化分解的计划
让我们以一个图书管理系统来做例子
“我想要一个图书管理系统” 是一个不够明确的目标。
即使是一句话需求,你的目标也应该更具体,例如“我想要一个图书管理系统,能够支持图书的借阅、归还和查询功能,同时支持用户注册和登录,并且能够记录借阅历史和逾期提醒。”
通过这句话我们至少能拆解成以下几部分
- 图书录入
- 图书管理员
- 图书管理
- 图书借阅功能
- 图书归还功能
- 图书查询功能
- 用户注册功能
- 用户登录功能
- 借阅历史记录功能
- 逾期提醒功能
有了上述内容,你基本就可以开始你的系统设计了,他们可以被分拆成多个模块,每个模块都可以独立展开,指定更详细的计划,通常来讲我会先建立每个模块的数据模型,然后开始设计每个模块的接口来操作他们。
基本上,每个模块都可以至少书写一片提示词,该提示词基本就是设计文档,一份出色的设计文档绝对足以指导 cluade code 开发该模块。
让我们从图书管理员的登录和列表功能为例书写一下这个设计文档,通常来说这会是我的方式:
图书管理员登录与管理列表的系统设计(提示词)
图书管理员是图书管理系统中的一个角色,负责管理图书的借阅和归还,以及用户注册和登录。
维护图书管理员的主要功能如下:
- 登录
- 图书管理员列表
- 增加
- 修改
- 删除
- 查询
- 重置密码
其数据结构基本如下:
登录
登录功能需要生成token,该token遵循令牌验证规则,以类Session的方式将登录用户信息存储至Redis中,方便查询。
我们应当新增AuthAdmin中间件用于在API 的Controller层前验证用户是否登录,并且在路由层理应可以自由配置该中间件。
登录后应当记录登录日志与令牌,方便后续维护单点登录与登录日志。
图书管理员列表 API
- 增加图书管理员 API
- 修改图书管理员 API
- 删除图书管理员 API
- 软删除,标注deleted_at
- 查询
- 可以根据用户名和登录账号进行搜索
- 默认过滤被删除的管理员用户
- 重置密码
- 使用用户输入的密码进行密码重置
如果你已经和团队成员沟通好了接口格式,那么应该一同在这个部分书写
验收
- 在完成每部分工作后,你需要进行(单元测/curl 请求),验证代码是否符合预期
- 如果部分代码无法完成测试,请务必说明原因
- 书写swagger文档,用于记录API信息
- 使用代码格式化工具,对未提交的改动部分进行代码格式化操作
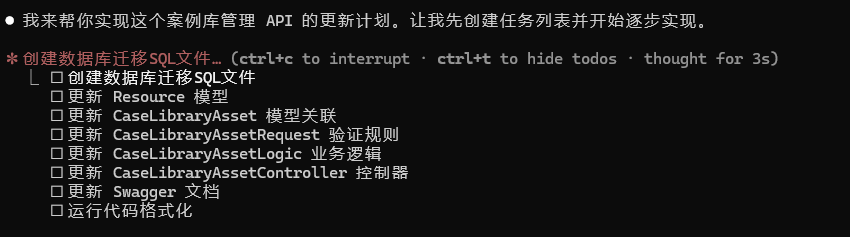
通常来讲这部分提示词以我的个人习惯,我回忆plan mode投喂给claude,然后仔细审查plan,在计划通过审查后,使用edit accept模式让其进行代码书写,
书写完成后我会整体执行单元测试,然后通过git审核代码是否符合要求,最后逐一对接口和数据库进行至少一次手动测试,确保其正确性。
最后将你的技术文档稍微完善,然后以团队协作的方式发布它。这份文档除去给人看之外,将来也可以在特性修改,升级时当做提示词交给Agent.
新特性工作流的总结
总的来说,在新特性的提示词部分我们需要如下几个过程:
- 总结基本的项目背景
- 梳理基本的功能特性
- 制定agent必须要完成的事项
- 说明重要的技术细节
- 以架构图/数据模型/交互流程/领域模型等方式 来定义必要的细节
最重要的,你的prompt不能太宽泛,所有你在乎的技术细节都应当被描述,通常agent产生幻觉或输出不符合预期都是提示词错写,漏写导致的。Claude opus和sonnet都极少出现幻觉, 因此你应该以更详实的提示词来规范它的工作。
伴随上述这片文档,再加以加工,直接将其投递给claude code通常就能表现的非常好,这通常和编程语言无关,相关性更高的是你有没有通过提示词完善你想要的需求。 但如果那你是刚入门的新手,你可能会疑惑,嘿,我怎么确保agent能书写符合项目规范的代码呢?下面我来继续展开聊这部分。
规范制定
规范部分需要兼顾以下几部分内容:
- 技术选型,版本和框架
- 代码规范注释规范等
- 数据库/中间件等其他技术栈的选型和具体的版本
- 开发流程定义(比如TDD)
- 验收标准定义
因此CLAUDE.md是非常重要的,如果你从一开始就没有叙述清楚项目是什么,如果进行开发,那么Agent表现会极差。 让我来展示一个我在Laravel框架中的CLAUDE.md的例子
CLAUDE.md
此文件为 Claude Code (claude.ai/code) 提供在此代码库中工作时的指导。
项目概述
这是一个基于 Laravel 12 框架的图书管理项目,用于图书管理。
技术栈:
- PHP 8.3+
- Laravel 12.0
- MySQL 5.7+
- Redis 5.0+
开发环境:
- 使用 Docker Compose 管理开发环境
- 服务容器:
- app (app): PHP-FPM 应用容器
- nginx (nginx): Nginx 服务器,端口 8000
- mysql (mysql): MySQL 5.7 数据库,端口 3306
- redis (redis): Redis 7 缓存,端口 6379
常用命令
本项目使用 Docker Compose 进行开发环境管理,所有 PHP/Artisan 命令都需要在 app 容器中执行。
Docker Compose 基础命令
# 启动所有服务
docker compose up -d
# 停止所有服务
docker compose down
# 查看服务状态
docker compose ps
# 查看服务日志
docker compose logs -f app
docker compose logs -f nginx
docker compose logs -f mysql
# 重启服务
docker compose restart app
开发环境
# 首次安装/设置项目
docker compose exec app composer run setup
# 运行测试
docker compose exec app php artisan test
# 运行特定测试文件
docker compose exec app php artisan test tests/Feature/ExampleTest.php
# 代码格式化(Laravel Pint)
docker compose exec app ./vendor/bin/pint
# 查看实时日志
docker compose exec app php artisan pail
队列管理
# 执行指定队列
docker compose exec app php artisan queue:work redis --queue=队列名称
# 队列监听(自动重启)
docker compose exec app php artisan queue:listen --tries=1
自定义 Artisan 命令
# 创建新命令
docker compose exec app php artisan make:command CommandNameSpace\CommandClassName
# 生成位置: app/Console/Commands/CommandNameSpace/CommandClassName.php
数据库管理
# 运行迁移
docker compose exec app php artisan migrate
# 进入 MySQL 容器
docker compose exec mysql mysql -u database -p
# 密码: assert_platform
Composer 和依赖管理
# 使用composer 例:
docker compose exec app composer install
进入容器 Shell
# 进入 app 容器
docker compose exec app bash
# 进入 MySQL 容器
docker compose exec mysql bash
# 进入 Redis 容器
docker compose exec redis sh
项目架构
分层结构(严格遵守)
项目采用清晰的分层架构,没有独立的 Service 和 Repository 层,Logic 层直接承担业务逻辑和数据访问职责:
请求流程: Route → Middleware → Controller → Request(验证) → Logic → Model → Database
各层职责:
- Route (
routes/*.php): 路由定义,分模块组织
routes/admin.php: 图书管理员相关路由,使用 AdminAuth 中间件routes/common.php: 通用路由,前缀/book-admin- 路由命名格式:
模块.控制器.方法,如admin.book-admin.list
- Middleware (
app/Http/Middleware/): 中间件,如认证、权限检查
Admin\Auth: 管理员认证中间件
- Controller (
app/Http/Controllers/): 控制器,职责单一,仅处理 HTTP 请求响应
- 继承
BaseController或对应的 Base 类(如BaseController) - 使用构造函数注入 Logic 和 Request 依赖
- 使用
readonly修饰符注入依赖 - 方法保持简洁,调用 Logic 层并返回响应
此处就不展开了,详细叙述你的框架规范和职责即可。
命名约定
- Controller 方法: 使用驼峰命名,如
list(),create(),updateStatus() - Logic 静态方法: 创建/更新等使用静态方法,如
AdminUserLogic::create(),AdminUserLogic::update() - 路由命名: 模块.控制器.方法,使用下划线分隔单词,如
admin.book-admin.update_status - 路由uri: 使用小写,使用下划线分隔单词,如
admin/book-admin/update_status - 数据库表名: 使用下划线小写,存放在
TableNameCost常量类中 - 模型关联: 使用驼峰命名,返回类型注解,如
role(): BelongsTo
编码规范
1. 使用中文注释和自然语言
所有注释必须使用中文,包括:
- 类注释
- 方法注释
- 参数注释
- 返回值说明
- 代码行内注释
/**
*图书管理员用户列表
*
* @param array $input 查询参数
* @return \Illuminate\Pagination
*/
public function list($input)
{
//查询图书管理员ID
$allUserIds = self::getAdminIds($input['pid'], false);
// ...
}
2. API 响应格式
所有 API 必须遵循统一的响应格式,使用 BaseController 提供的方法:
// 成功响应
return $this->success($data, 'success', 0);
// 简写
return $this->success($data);
// 错误响应
return $this->error('错误信息', CodeConst::ERROR);
响应结构:
{
"error": 0,
"message": "success",
"result": {}
}
此处就不展开了,详细叙述你的示例代码即可
开发流程和测试要求
创建新功能的标准步骤
- 创建 Request 验证类 (
app/Http/Requests/)
- 定义不同 action 的验证规则
- 定义自定义错误消息
- 创建 Logic 业务逻辑类 (
app/Logic/)
- 实现核心业务逻辑
- 直接操作 Model
- 处理缓存
- 创建 Controller 控制器 (
app/Http/Controllers/)
- 依赖注入 Logic 和 Request
- 保持方法简洁
- 返回统一格式响应
- 添加路由 (
routes/)
- 选择合适的路由文件
- 使用中间件保护
- 设置路由命名
- 测试
- curl测试 API 接口
- 验证请求参数校验
- 验证业务逻辑正确性
- 验证缓存是否生效
- 使用 MCP database 工具验证数据库变更
- 如果业务逻辑较为复杂,考虑编写单元测试和集成测试,并进行验证
测试示例
# 使用 curl 测试 API(注意端口是 8000)
curl -X GET "http://localhost:8000/xxxx?fields[]=xxx&fields[]=xxxx" \
-H "Authorization: Bearer {token}"
# 在 Claude Code 中使用 MCP 工具查询数据库
# mcp__database__execute_sql
SELECT * FROM tags WHERE field = 'xxxx';
# 查看 Redis 缓存
docker compose exec redis redis-cli
> KEYS "xxx:xxx:*"
> GET "xxx:xxx:xxxx"
详细叙述你的开发流程和测试要求,包括单元测试、集成测试、性能测试等。
注意事项
- Docker 环境: 所有命令必须通过
docker compose exec app在容器中执行,不要直接在宿主机运行 PHP/Artisan 命令 - 访问端口: 应用通过 http://localhost:8000 访问,不是默认的 80 端口
- 分层明确: 严格遵守分层架构,不要跨层调用(例如 Controller 不能直接操作 Model)
- 中文注释: 所有注释必须使用中文
- 测试优先: 实现功能后立即进行测试,包括参数校验、业务逻辑、缓存验证
- 使用 MCP 工具: 优先使用
mcp__database__工具查询数据库,而非直接执行 SQL 命令 - 缓存清理: 当数据结构变更时,记得清理旧缓存(可通过
docker compose exec redis redis-cli进入 Redis) - 安全性: 避免 SQL 注入、XSS 等安全问题,使用参数绑定和验证
- 性能优化: 只查询需要的字段,使用预加载,合理使用缓存
- 错误处理: 使用
abort_code()统一处理错误,提供清晰的错误信息 - 分布式锁: 对于并发操作使用分布式锁保证数据一致性
- 代码风格: 使用 Laravel Pint 保持代码风格一致(
docker compose exec app ./vendor/bin/pint) - 日志查看: 使用
docker compose logs -f app查看应用日志,或在容器内使用php artisan pail
通常来讲,只要你书写了一份像这样的代码规范,并且在每次遇到问题后就去维护它,你的agent变成表现会越来越好。
一定记得,每当你像书写类似"请你参考xxxx文件的风格来完成编码"这样的提示词,就去维护它,一旦出现这种情况基本能说明你的没有在CLAUDE.md中叙述清楚项目规范本身。
Debug的工作流
每当你试图修复一个bug时,通常要以下几个步骤:
- 收集BUG特征
- 不仅仅是报错和日志这么简单,有的时候特定的数据和有状态的缓存同样重要。
- 数据需要被脱敏。
- 在本地的开发环境试着复现该bug
- 分析bug的成因
- 尝试修复bug
- 验证修复的结果
坦率讲这就是这个工作流的主要节点了,它们的顺序不一定,但是这几个关键节点基本不可或缺。Agent也可以这么工作,完全没有问题。
通常来接收集BUG特征阶段,你需要语义描述出prompt,然后将生产环境中的报错,日志,数据(这些内容需要脱敏整理,这很关键)这些内容统一整理到prompt中 并且书写详细的提示词让Agent试着分析或者复现bug,一旦Agent复现成功或者分析成功, 就可以启动plan mode让Agent制定计划,并且修复它,最后用同样的测试方法再次让Agent试着复现,进行这个循环直到bug被修复。
复杂任务
让我首先来说明一下,没有复杂任务。是的,在现在软件工程中没有复杂任务。
所有任务在正确的架构设计下,原则上都应该得到类似分治法的拆分,将其的复杂程度控制到一定范围内。
也许你会说,哦,如果我拆分的A模块和B模块无法衔接怎么办?
这是典型的架构设计缺陷,幻想一下,如果你有AB两个团队同时进行工作,我们是怎么约束他们能够相互对接的呢?
下列示意图用于一个简单的例子:
- a: 完全不拆解需求,提示词范围过大,模糊且单次提示词上下文过长,容易幻觉
- h | i | j | k | g :拆解成5次提示词,提示词精准且模型理解准确,且代码约束性较好
Grpc Proto, Json API, 如果是代码内部,那么使用 interface 提前约束接口是最理想的。只要你的拆分 方式满足了职责单一,规则明确,那么无所谓你使用什么方式进行约定,哪怕约定仅仅存在于Prompt中也不会出现任何问题。
是的,所有关于“复杂任务”如何进行拆分的问题,早已经在漫长的软件工程学历史上被以不同的设计范式解决了无数次。那些古董又刻板的知识 从来都不曾过时,你可以继续使用它们解决你在AI Coding中遇到的协作问题。
因此,很快你就能理解,最复杂的任务,莫过于维护你曾经写的那些没有技术文档,产品文档整理不足,代码设计及其糟糕,完全没有规范的项目。 现实意义上不仅对AI Coding,即使是纯粹人力的Coding,脱离了原始的项目负责人它依旧是一坨无法维护的代码。而对于那些认真解决技术债务的团队, 是的,你们已经提前走在了正确的道路上,AI会把这两个团队的差距拉开的更大,无论是代码质量还是迭代速度上。
让我来重新总结一下如何解决复杂任务
- 最小化上下文,按照职责/领域/模块拆分你的任务
- 树立好锚点,确保两个需要对接模块间接口是明确而清晰的上下文
- 良好的可测试性和交付标准
你回溯一下,这和写一个新特性没有任何区别。
作为配合AI Coding的人类,你需要良好的代码“品鉴能力”能清晰地识别出哪些是必须解决的坏味道。
你最重要的三项职责就是:清晰设计!文档化!严格验收!